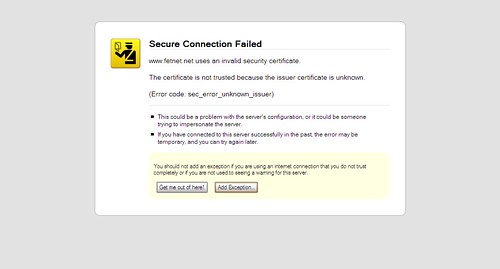
遠傳電信的數位相框網站登入部份有過SSL,但是因為 Server Certificate Chain 設錯的關係,所以會出現憑證無效的訊息:
早上發現的,剛剛開始寫 Blog 的時候又去了一次,這次看起來修好了……
遠傳電信的數位相框網站登入部份有過SSL,但是因為 Server Certificate Chain 設錯的關係,所以會出現憑證無效的訊息:
早上發現的,剛剛開始寫 Blog 的時候又去了一次,這次看起來修好了……
中了個令人無言的地雷……
FreeBSD 有一個well-known的參數調整:mbuf clusters的最大值(kern.ipc.nmbclusters)。當使用的mbuf clusters超過設定的最大值時,網路就會不通。不過,我們可以在 /boot/loader.conf 裡面把 kern.ipc.nmbclusters 設為 0,表示不設定最大值,這樣他就會被Kernel Space Memory的大小限制住(一個 mbuf cluster 要吃約 2KB 的Kernel Memory)。
最近我們發現這樣設定的機器在有大量 TCP out-of-order 封包的網路環境下,網路效能表現非常差,於是做了很多交叉比對以及測試。最後發現有這樣問題的機器有兩個特點:netstat -s -p tcp 的結果,out-of-order packets 的 counter 都是 0,而且packets discarded due to memory problems 的 counter 很多。
最後找到 Maillist上的資料,發現在 kern.ipc.nmbclusters 設定為 0 的情況下,net.inet.tcp.reass.maxsegments 也跟著被設定成 0 了,調整回預設值 1600 就解決這個問題了。
今天因為某組Web機器當機實在當太嚴重了,因為我們發現問題是出在NFS,所以我們把 KDB 跟 DDB 編進去準備來找問題。
當發生問題的時候,由於機器不會當死,所以可以在Console按Ctrl-Alt-ESC進DDB。進了DDB以後,可以用textdump(4)來紀錄所下的指令以及其output。紀錄的資料會dump在dump device(通常是swap),等下次開機的時候會存到/var/crash裡面。
大概的作法是這樣:
如果發現出來的結果會被截掉的話,要把textdump的capture buffer加大:
sysctl debug.ddb.capture.bufsize=196608
雖然說已經 Generally Available,PIXNET已經踩到好幾次地雷了……
除了 InnoDB 有用錯Index的情形,甚至還有吃到 signal 11就再起不能的事 Orz
如果你現在有空機器,可以試試看 MySQL 5.1 比 5.0 好的 Performance (尤其是 SMP)
而 5.1 的 MyISAM 的表現跟穩定性也不錯。
但是如果你用的是InnoDB,請以alpha的態度對待5.1.30 GA……
把 FreeBSD 從 7.0-RELEASE 升級到 7.1-BETA2 以後,發現只有 Local Account 會去查該 Account 屬於 ldap 裡面的 group,而 LDAP Account 不會,只會查 Local Group 跟 Main Group(gidNumber 指定的 Group)。
找了半天,改了 nsswitch.conf 與 nss_ldap.conf,還是不會動,最後自暴自棄開始翻 Mailling list,結果看到這篇:[Working fix] Problems combining nss_ldap/pam_ldap with pam_mkhomedir in FreeBSD 7.0
Developers doesn’t like "soft".
當場囧在那邊。最後把 soft 改成 hard,這個問題就解決了….Orz
想法很簡單,先把空硬碟作成 Software RAID 1,接著把資料倒過去,最後再把舊的硬碟加到 Disk Array 中。
假設 sda 是原本的硬碟,sdb 是新硬碟:
# sfdisk -d /dev/sda | sfdisk /dev/sdb
# mdadm -C /dev/md0 –level=raid1 –raid-devices=2 /dev/sdb1 missing
# mkfs -t ext3 /dev/md0
# mount /dev/md0 /mnt
# rsync -ax / /mnt/
# vim /etc/fstab
# vim /boot/grub/menu.lst把 fstab 與 menu.lst 內的 /dev/sda1 都換成 /dev/md0
# reboot
確認 md0 有正確掛起來
# mdadm –manage /dev/md0 –add /dev/sda1
這樣就大功告成了。
源於 OpenBSD,port 到 FreeBSD 的 pf 本身就可以作 load balancer,但是不能作 healthy check。要作 healthy check 的話,必須加上 relayd。另外用 CARP(4) 與 PFSYNC(4) 可以做到 Active-Standby 的 Redundancy HA,也就是當一台 SLB (Server Load Balancer) 死掉的時候,另一台會自動起來提供服務。詳細的作法在參考資料有,因此這裡不贅述。基本的想法為:
這樣就可以達到 Layer 4 Switch 的功能,在 relayd 裡面稱為 REDIRECT 模式,缺點是 pool 內所有的 server 都必須把 default gateway 設為 SLB。
另外 relayd 也可以採用類似 haproxy 的方式,由 relayd 跟 client 與 server 各建立一個連線,作 Layer 7 的 forwarding。這在 relayd 裡面稱為 RELAY 模式。
設定 relay 模式的時候,可以對 HTTP Header 作修改,例如加上 X-Forwarded-For Header,或是根據 Host Header 或者 URI 來決定要分配到的 Pool。另外 healthy check 也可以由管理者自行撰寫 script,因此可以作比較複雜的檢查。設定方式可以參考 RELAYD.CONF(5)。
比起 haproxy 來說,relayd 可以輕易的達到 Full Transparent Proxy (後端的 Server 看到的 source ip 是真正的 ip)的功能而不需要 patch kernel,而且也可以作 graceful restart( haproxy 在 restart 的時候服務會中斷);不過 haproxy 有許多的實例已經驗證過它的效能,可以吃滿 10Gbps 網路,但 relayd 在 RELAY 模式的 效能還是未知數。另外,由於 relayd 與 pf 綁的很緊,因此目前只有 OpenBSD 與 FreeBSD 版,不能在 Linux 上執行。
參考資料:
最近事忙,忘了上來寫…
大約一個月之前,PIXNET 買的 Memoright 有一顆發生故障,硬碟直接從 OS 端消失,完全看不到了 XD
重開之後,BIOS也抓不到。懷疑是 SATA 連接線的問題,所以重新插了一次,就 OK 了,用到目前還沒有中地雷。
結果大概一週前, Mtron MSP-SATA70 32G 也掛了一顆 XD
Linux 抱怨寫入會有 Error,於是也重開機,重接線,結果運氣不好,還是會有 Error。現在這顆 SSD 已經飄洋過海回韓國檢查了…
情形:有兩顆同樣大小的硬碟,想切出 10G 當 / 並作 gmirror,其他作 ZFS。
作法:先灌好 FreeBSD,把硬碟切成同一個 partition,例如說 ad0s1。 / 放在 ad0s1a,swap 放在 ad0s1b,ZFS 放在 ad0s1d。假設另一顆硬碟是 ad1,也同樣切成 a,b,d 三個與 ad0 slice 大小相同的 slice。
# gmirror load
# gmirror label -v -h -b round-robin gm0s1a ad1s1a
# newfs -U -O2 /dev/mirror/gm0s1a
# mount -o noatime /dev/mirror/gm0s1a /mnt
# echo ‘geom_mirror_load="YES"’ >> /boot/loader.conf
# vi /etc/fstab把 /dev/ad0s1a 都改成 /dev/mirror/gm0s1a
# cd /
# tar -c –one-file-system -f – . | tar xpf – -C /mnt/重開後,再把 ad0s1a insert 回去:
# gmirror insert gm0s1a ad0s1a
# gmirror rebuild gm0s1a ad0s1a接著建立 ZFS:
# zpool create tank ad0s1d ad1s1d
這樣就完成了。
今天就是 Firefox 3 的正式發表日期了,大家快去下載吧!