VirtualBox 是 Sun (後來被 Oracle 買下) 開發的一套虛擬化軟體。他的 Host OS 可以是 Windows, Linux, MacOS, FreeBSD。除此之外,VirtualBox 可以在 Terminal 下執行,顯示的畫面由 RDP/VNC 輸出,亦即 Headless 模式。要特別注意的是,RDP 輸出僅限於專屬授權版本,OSE (Open Source Edition) 版本是沒有這個功能的。
要使用 VNC 輸出,必須在安裝的時候加入 VNC 支援:
# cd /usr/ports/emulators/virtualbox-ose; make WITH_VNC=yes all install clean
安裝好 VirtualBox 之後,必須再安裝 kernel module:
# cd /usr/ports/emulators/virtualbox-ose-kmod; make install clean
接著把需要的 Kernel Module 載進來:
# kldload vboxdrv; kldload vboxnetadp; kldload vboxnetflt
之前寫在 /boot/loader.conf 會導致開機時 Kernel Panic,但如果開完機手動載入就不會,目前還沒找出原因。
接下來新增一個 Virtual Machine:(以下都可以不需要 root 權限)
% VBoxManage createvm winxp --register
然後設定 VM 的資源需求:
% VBoxManage modifyvm winxp --acpi on --ioapic on --memory 1024 --cpus 2 --nic1 bridged --nictype 82540EM --bridgeadapter1 em1
以上的範例分配了 1024MB (1GB) 的 RAM 與 2 個 Virtual CPU 給 winxp 這個 VM,另外建立了一張虛擬網卡,型號為 Intel 82540EM,橋接到實體的 em1 這張網卡上。
再來建立一個新的 120GB 虛擬硬碟:
% VBoxManage createhd --filename winxp --size 122880
在 VM 裡增加一個 IDE Controller:
% VBoxManage storagectl winxp --name "IDE Controller" --add ide
把硬碟與安裝 ISO 檔連接到 IDE Controller:
% VBoxManage storageattach winxp --storagectl "IDE Controller" --port 0 --device 0 --type hdd --medium winxp
% VBoxManage storageattachwinxp --storagectl "IDE Controller" --port 1 --device 0 --type dvddrive --medium winxp.iso
接著就可以開機了:
% VBoxHeadless -s winxp --vnc --vncport 5900 --vncpass password
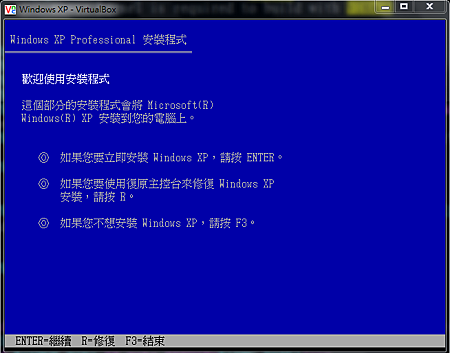
執行成功後,可以用 VNC 連入看到安裝 Windows XP 的畫面:
關機、重開機可以使用 VBoxManage 來完成:
% VBoxManage controlvm winxp poweroff